 E-mail
E-mail  Chat
Chat  Suporte ao cliente
Suporte ao cliente Faça a escolha certa para sua necessidade
Cold (Apenas replicação de dados)
Warm (Replicação dos dados assíncrona)
Hot (Replicação dos dados síncronas)
Always On (Replicação em Real Time e FailOver automático)

Hoje em dia, a maioria das empresas depende da tecnologia e de uma infraestrutura de TI eficiente e robusta para garantir seus processos e a produtividade dos colaboradores. Neste cenário, o termo Disaster Recovery ganha força e precisa fazer parte da rotina dessas organizações.
Com processos cada vez mais automatizados, a tecnologia torna-se fundamental para o bom funcionamento de uma companhia. Ela impacta diretamente na eficácia das operações e na experiência proporcionada aos clientes.
Porém, ao pensar em aparatos tecnológicos, é comum a ocorrência de falhas e imprevistos que comprometem as atividades da empresa. Muitos negócios, por exemplo, sofrem com perda de dados e arquivos e não estão preparados para esses incidentes.
Para contornar esse tipo de situação, entender o que significa Disaster Recovery e suas vantagens para as organizações é muito importante.
Esclareça suas duvidas com nossa consultoria
- O que é Disaster Recovery ?
- Como a recuperação de desastres pode ajudar?
- Garantindo a integridade da sua infraestrutura
- Como implementar um plano de Disaster Recovery ?
Cybersecurity

O termo Disaster Recovery significa, em tradução livre para o português, recuperação de desastres. Trata-se, na área de Tecnologia da Informação, de um conjunto de ações estratégicas estabelecidas que tem por objetivo evitar que uma empresa perca todos os seus dados e informações quando ocorre um imprevisto.
Essas estratégias são preventivas e recuperativas tendo como objetivo restabelecer os serviços da empresa.

Você já sabe que uma solução de recuperação de desastres é essencial. No entanto, pode estar se perguntando o que exatamente ela faz, certo?
Na prática, os grandes objetivos da disaster recovery são, claro, assegurar a recuperação dos dados perdidos e a continuidade das operações para, no final de tudo, promover a manutenção do controle dos processos internos e até mesmo a estabilidade da empresa como um todo, dependendo da dimensão do imprevisto.
Assim, as medidas de recuperação de desastres estão divididas em três frentes interligadas:
1. Prevenção: conjunto de ações contra eventos cujos efeitos podem ser evitados, como o estabelecimento de uma robusta camada de cibersegurança contra ataques de hackers.
2. Detecção: medidas que ajudam a detectar o quanto antes – imediatamente, de preferência – eventuais problemas na infraestrutura de TI da empresa.
3. Correção: providências a serem tomadas diante de um desastre, independente de sua natureza.
Dentro desse conjunto é indispensável incluir um plano de continuidade e restabelecimento das operações. Ele deve incluir um planejamento para a reorganização dos dados recuperados e um protocolo de ações para a administração de eventuais crises.
Além disso, esse plano também é importante para mapear outras possíveis vulnerabilidades da sua infraestrutura e, assim, conseguir implementar um mapa de prevenção (o primeiro item acima) verdadeiramente eficaz.

O Microsoft Azure é a plataforma de nuvem híbrida mais segura e inteligente do mercado. Dentre os seus recursos, ele conta com uma robusta solução de recuperação de desastres dividida em três frentes:
1. Backup do Azure
2. Recuperação de site do Azure
3. Armazenamento de Arquivos do Azure
Graças à associação entre o expertise da Microsoft no setor da tecnologia e os investimentos bilionários que a empresa anualmente faz em segurança, a solução de disaster recovery do Azure consegue ser simples, econômica e escalonável sem abrir mão da qualidade do serviço.
Além disso, mesmo as empresas que já contam com algum tipo de solução de backup conseguem aproveitar os recursos do Azure a partir de uma integração fácil e rápida que ajudará a reforçar a segurança dos dados.

Depois de conhecer a realidade e necessidades da empresa, assim como suas vulnerabilidades em relação aos dados, chegou o momento de desenhar o plano de Disaster Recovery.
Por meio dele, serão listadas todas as ações que devem ser tomadas em caso de imprevistos e falhas, evitando seus impactos negativos na operação e garantindo uma rápida recuperação dos arquivos e informações.
Qual é o diferencial da nuvem da Microsoft?
O Microsoft Azure é uma plataforma consolidada, estável e segura, que oferece estrutura robusta para suporte dos processos. A tecnologia concretiza a gestão e armazenamento de dados, serviços de webmail e softwares, desenvolvimento e execução de aplicativos.
Na prática, o Azure se operacionaliza conectando servidores remotos espalhados em diferentes pontos e facilitando a operação em conjunto entre os dispositivos. Ele se baseia em tecnologias de Infraestrutura e Plataforma como serviço, o que permite rodar sistemas e aplicações, processar dados, substituir equipamentos e dispositivos físicos. Dessa forma, a solução proporciona eficiência operacional e redução de custos.
Outro ponto importante é que o Azure se destaca, principalmente, pela estrutura de segurança altamente reforçada, que oferece proteção contra 99,9% dos ataques de segurança cibernética, a grande agilidade operacional e a integração com todo o ecossistema Microsoft.

Quais são os benefícios do Azure Disater Recovery?
O Disaster Recovery quando bem implantando, proporciona diversos benefícios para as empresas:

Custos reduzidos
Com um plano de Disaster Recovery e as soluções em nuvem, a organização paga somente o que for usado, além da facilidade de aumentar o serviço quando necessário.

Implementação facilitada
Selecionar um parceiro especialista em infraestrutura de TI, que ficará responsável pela execução de toda a estratégia.

Segurança para os dados
Manter os dados da organização seguros, os colaboradores ganham produtividade e confiança para desempenharem suas funções

Vendas
A Microsoft desenvolveu segmentações na nuvem que contemplam os setores de venda e varejo e proporcionam mais flexibilidade para a empresa, além de atender às necessidades de vendedores e comércios.

Operações de manufatura
A segmentação do Microsoft Cloud para Manufatura integra as operações do negócio, auxiliando no controle de processos e gerenciamento de riscos.

Setor de TI e Desenvolvimento
O DevSecOps é uma solução do Azure que une desenvolvimento e operação, possibilitando uma atuação coordenada, segura e colaborativa. A plataforma envolve aplicações para planejamento, desenvolvimento, codificação, implantação do app no ambiente de produção e monitoramento da solução.

Gerência, estratégia e tomada de decisão
O Power BI integrado ao Azure agrega dados de múltiplas dimensões do negócio, simplificando o trabalho de lideranças nas análises, avaliações e desenvolvimento de planos de ação para o empreendimento.

Conformidade
A plataforma apresenta tecnologias para varredura, inventário e análise, o que te ajuda a estar em conformidade com a Lei Geral de Proteção de Dados e proporciona uma gestão segura de processos de tecnologia da informação.
Estratégias do Disaster Recovery
- O que é Disaster Recovery ?
- Como a recuperação de desastres pode ajudar?
- Garantindo a integridade da sua infraestrutura
- Como implementar um plano de Disaster Recovery ?
Cybersecurity
O termo Disaster Recovery significa, em tradução livre para o português, recuperação de desastres. Trata-se, na área de Tecnologia da Informação, de um conjunto de ações estratégicas estabelecidas que tem por objetivo evitar que uma empresa perca todos os seus dados e informações quando ocorre um imprevisto.
Essas estratégias são preventivas e recuperativas tendo como objetivo restabelecer os serviços da empresa.
Você já sabe que uma solução de recuperação de desastres é essencial. No entanto, pode estar se perguntando o que exatamente ela faz, certo?
Na prática, os grandes objetivos da disaster recovery são, claro, assegurar a recuperação dos dados perdidos e a continuidade das operações para, no final de tudo, promover a manutenção do controle dos processos internos e até mesmo a estabilidade da empresa como um todo, dependendo da dimensão do imprevisto.
Assim, as medidas de recuperação de desastres estão divididas em três frentes interligadas:
1. Prevenção: conjunto de ações contra eventos cujos efeitos podem ser evitados, como o estabelecimento de uma robusta camada de cibersegurança contra ataques de hackers.
2. Detecção: medidas que ajudam a detectar o quanto antes – imediatamente, de preferência – eventuais problemas na infraestrutura de TI da empresa.
3. Correção: providências a serem tomadas diante de um desastre, independente de sua natureza.
Dentro desse conjunto é indispensável incluir um plano de continuidade e restabelecimento das operações. Ele deve incluir um planejamento para a reorganização dos dados recuperados e um protocolo de ações para a administração de eventuais crises.
Além disso, esse plano também é importante para mapear outras possíveis vulnerabilidades da sua infraestrutura e, assim, conseguir implementar um mapa de prevenção (o primeiro item acima) verdadeiramente eficaz.
O Microsoft Azure é a plataforma de nuvem híbrida mais segura e inteligente do mercado. Dentre os seus recursos, ele conta com uma robusta solução de recuperação de desastres dividida em três frentes:
1. Backup do Azure
2. Recuperação de site do Azure
3. Armazenamento de Arquivos do Azure
Graças à associação entre o expertise da Microsoft no setor da tecnologia e os investimentos bilionários que a empresa anualmente faz em segurança, a solução de disaster recovery do Azure consegue ser simples, econômica e escalonável sem abrir mão da qualidade do serviço.
Além disso, mesmo as empresas que já contam com algum tipo de solução de backup conseguem aproveitar os recursos do Azure a partir de uma integração fácil e rápida que ajudará a reforçar a segurança dos dados.
Depois de conhecer a realidade e necessidades da empresa, assim como suas vulnerabilidades em relação aos dados, chegou o momento de desenhar o plano de Disaster Recovery.
Por meio dele, serão listadas todas as ações que devem ser tomadas em caso de imprevistos e falhas, evitando seus impactos negativos na operação e garantindo uma rápida recuperação dos arquivos e informações.
Planos de Disaster Recovery que a nossa consultoria fornece
Um plano de Disaster Recovery eficiente é composto por três etapas:

GESTÃO DE CRISE
É importante listar quem são os responsáveis por ela e os departamentos mais impactados, para que eles recebam uma atenção especial.

Manutenção da continuidade operacional
Essa etapa é responsável por realizar as rotinas e garantir que todos os serviços estão funcionando

Recuperação de serviços
Nesta etapa os itens que foram danificados recebem uma atenção maior
DRAAS BASEADO EM VEEAM
Implantar um DRaaS (Disaster Recovery as a Service) baseado em Veeam com a Penso é uma excelente opção para empresas que buscam segurança e eficiência.
Entre os principais recursos estão backup confiável, recuperação rápida, replicação segura, portabilidade na nuvem, storage inteligente e reutilização de dados.
Não existe configuração extra, os próprios backups serão utilizados para os servidores em nuvem e realizados a partir da imagem do ambiente. Isso fornece mais garantia de funcionamento em casos de desastre.
Além disso, com o Veeam, a sua empresa pode unificar backup e replicação de diversos ambientes distintos, como servidores virtuais, físicos e até mesmo concentrar servidores hospedados em diversas nuvens (AWS/Azure/Google).
Agora que você já sabe o que é Disaster Recovery e os seus benefícios para as empresas, proteja os dados da sua organização com o Veeam Backup, a solução líder mais confiável do mercado.
Conceitos
O intuito desse tópico é expor alguns conceitos, os quais serão utilizados no decorrer desse documento:
- Ambiente de Recovery – Ambiente que ficará ativo/disponível no caso de desastre.
- Continuidade do Negócio – Garante que uma corporação mantenha ou restaure as funções críticas do negócio após algum incidente grave.
- DR – Disaster Recovery – Consiste em uma série de políticas e procedimentos com o intuito de restaurar o estado original de alguma aplicação, ou serviço após catástrofe.
- On-Premises – Refere-se ao ambiente fora de nuvem computacional, geralmente utilizando-se de modalidades como hosting, colocation ou infraestrutura de computação dentro da corporação.
- PCO – Plano de Continuidade Operacional – Plano de ação que define procedimentos, visando garantir que, no caso de incidente, os serviços essenciais sejam preservados.
- RP – Recovery Point
- RPO – Recovery Point Objective – A quantidade de dados perdida em um determinado período de tempo, após interrupção. Por exemplo, se um desastre acontece às 01:00 e o RPO é de uma (1) hora, o workload deve ser restaurado de forma íntegra, com os dados de até 00:00, ou seja, a perda de dados, será de no máximo uma (1) hora.
- RT – Recovery Time
- RTO – Recovery Time Objective – O tempo acordado no plano de continuidade operacional que leva, após interrupção, para restaurar o workload para o nível de serviço aceitável, após evento de desastre. Por exemplo, se um desastre acontece às 00:00 e o RTO é de oito (8) horas, o ambiente precisa ser restaurado aos níveis aceitáveis até 8:00.
CONTINUIDADE DE NEGÓCIOS: ESSENCIAL!
Em primeiro lugar, precisamos entender o que é a recuperação de desastres.
Com o rápido avanço da transformação digital, principalmente em meio à pandemia do coronavírus, as empresas estão cada vez mais dependentes da tecnologia para a continuidade das operações. Por isso, o estabelecimento de um plano de contingência diante de imprevistos se tornou mais um item da checklist de ações indispensáveis dentro de qualquer organização.
Como o próprio nome nos indica, a recuperação de desastres é uma série de processos estruturados cujo objetivo é, basicamente, garantir a recuperação de dados perdidos sob circunstâncias variadas – os chamados “desastres”.
Dentre os desastres mais comuns no meio corporativo, temos:
- Erro humano, como a exclusão permanente de arquivos sem querer.
- Ataques cibernéticos, como ransomware (que exige o pagamento de um “resgate” para a liberação de acesso a arquivos e sistemas).
- Falhas na energia elétrica, muito comuns nas épocas mais quentes do ano.
- Desastres naturais, como tempestades e terremotos que abalam a estrutura de centros de dados físicos, por exemplo.
A lista anterior é importante para desmistificar a ideia de que apenas um ataque de hackers pode ser classificado como desastre ou acarretar na perda de documentos.
Além disso, mesmo os atentados digitais são mais comuns do que pensamos! Assim, independente do porte da sua empresa, contar com uma solução de recuperação adequada para o seu setor é essencial.
Outro detalhe importante nesse sentido está relacionado à LGPD, a Lei Geral de Proteção de Dados Pessoais. Quando se armazena dados pessoais de clientes e colaboradores, por exemplo, assume-se a responsabilidade de mantê-los protegidos. Qualquer falha nesse sentido – por qualquer motivo – pode significar um prejuízo milionário para as companhias.
Então, fique atento(a): um desastre digital pode, sim, acontecer na sua empresa.
Expertise que você pode confiar
A cloud computing permite o surgimento de novos modelos de negócios que podem desafiar as formas tradicionais de fazer as coisas. Agora é a hora de aproveitar o poder da nuvem para obter vantagem competitiva. A Gateway IT entende que a qualidade do serviço prestado por um parceiro de tecnologia reflete diretamente sobre o seu trabalho e o desempenho da organização.

Arquiteturas de DR (Disaster Recovery) – conheça casos práticos

Introdução
Para a grande maioria das corporações, questões de continuidade de negócios e backup são bastante críticas. Hoje em dia, diversas empresas estão utilizando a computação em nuvem para esse tipo de demanda, pois além da praticidade e flexibilidade, está aliada a otimização de custo.
O intuito desse material é expor conceitos de Disaster Recovery, algumas arquiteturas utilizadas no modelo de computação em nuvem, assim como casos práticos, expondo a intercomunicação com o ambiente on-premisese nuvem, para o melhor entendimento da aplicabilidade dos serviços para esse fim.
Conceitos
O intuito desse tópico é expor alguns conceitos, os quais serão utilizados no decorrer desse documento:
- Ambiente de Recovery – Ambiente que ficará ativo/disponível no caso de desastre.
- Continuidade do Negócio – Garante que uma corporação mantenha ou restaure as funções críticas do negócio após algum incidente grave.
- DR – Disaster Recovery – Consiste em uma série de políticas e procedimentos com o intuito de restaurar o estado original de alguma aplicação, ou serviço após catástrofe.
- On-Premises – Refere-se ao ambiente fora de nuvem computacional, geralmente utilizando-se de modalidades como hosting, colocation ou infraestrutura de computação dentro da corporação.
- PCO – Plano de Continuidade Operacional – Plano de ação que define procedimentos, visando garantir que, no caso de incidente, os serviços essenciais sejam preservados.
- RP – Recovery Point
- RPO – Recovery Point Objective – A quantidade de dados perdida em um determinado período de tempo, após interrupção. Por exemplo, se um desastre acontece às 01:00 e o RPO é de uma (1) hora, o workload deve ser restaurado de forma íntegra, com os dados de até 00:00, ou seja, a perda de dados, será de no máximo uma (1) hora.
- RT – Recovery Time
- RTO – Recovery Time Objective – O tempo acordado no plano de continuidade operacional que leva, após interrupção, para restaurar o workload para o nível de serviço aceitável, após evento de desastre. Por exemplo, se um desastre acontece às 00:00 e o RTO é de oito (8) horas, o ambiente precisa ser restaurado aos níveis aceitáveis até 8:00.
Serviços da AWS
Antes de discutir as várias abordagens de DR, é importante listar os serviços da AWS com maior relevância para implementação de Arquiteturas de Disaster Recovery.

Banco de dados
Amazon RDS
O Amazon Relational Database Service (AWS RDS) facilita a configuração, a operação e a escalabilidade de bancos de dados relacionais na nuvem. O serviço oferece capacidade econômica e redimensionável e automatiza tarefas demoradas de administração, como provisionamento de hardware, configuração de bancos de dados, aplicação de patches e backups. Dessa forma, você pode se concentrar na performance rápida, alta disponibilidade, segurança e conformidade que os aplicativos precisam.
O Amazon RDS está disponível em vários tipos de instância de banco de dados – com otimização para memória, performance ou E/S – e oferece seis mecanismos de bancos de dados comuns, incluindo Amazon Aurora, PostgreSQL, MySQL, MariaDB, Oracle Database e SQL Server. Você pode usar o AWS Database Migration Service para migrar ou replicar facilmente bancos de dados existentes para o RDS.

Computação
Amazon EC 2
Amazon Elastic Compute Cloud (EC2) é uma parte central da plataforma de cloud computing da Amazon.com, Amazon Web Services (AWS). O EC2 permite que os usuários aluguem computadores virtuais nos quais rodam suas próprias aplicações. O EC2 permite a implantação de aplicações escaláveis ao prover um Web service através do qual um usuário pode iniciar uma Amazon Machine Image para criar uma máquina virtual, que a Amazon chama uma “instância”, contendo qualquer software desejado. Um usuário pode criar, lançar e terminar instâncias do servidor, conforme necessário, pagando por hora pelos servidores ativos, daí o termo “elástico”. O EC2 oferece aos usuários o controle sobre a localização geográfica da instâncias o que permite a otimização de latência e altos níveis de redundância.

Amazon Machine Images (AMI)
O Amazon Machine Image (AMI) é um tipo especial de dispositivo virtual usado para criar uma máquina dentro do Amazon Elastic Compute Cloud (“EC2”). Ele serve como a unidade básica de implantação para serviços entregues usando EC2.
Possui a versão gratuita que pode ser usado por qualquer pessoa, a versão paga que está registrado no Amazon DevPay e pode ser usado por qualquer pessoa que o assine, o DevPay permite que os desenvolvedores aumentem as taxas de uso e, opcionalmente, adicionem taxas de assinatura mensal, também a versão compartilhada uma conta privada que só pode ser usado por usuários do Amazon EC2 com acesso permitido pelo desenvolvedor.

AWS Elastic Beanstalk
O AWS Elastic Beanstalk é um serviço de orquestração oferecido pela Amazon Web Services para a implantação de aplicativos que orquestram vários serviços da AWS, incluindo EC2, Amazon S3, Simple Notification Service (SNS), CloudWatch, escalonamento automático e Elastic Load Balancers.Seu nome em inglês significa “pé de feijão elástico”, é uma referência ao pé de feijão que cresceu até as nuvens no conto de fadas João e o pé de feijão.
O Elastic Beanstalk fornece uma camada adicional de abstração sobre o servidor e sistema operacional; os usuários, em vez disso, veem uma combinação pre-construída de sistema operacional de 64 bits e plataforma, como o Amazon Linux executando Ruby, ou o Debian executando Python.
A implantação requer uma série de componentes a serem definidos: um “aplicativo” como um contêiner lógico para o projeto, uma “versão” que é uma compilação implantável executável do aplicativo, um “modelo de configuração” que contém informações de configuração para o ambiente Beanstalk e para o produto. Finalmente, um “ambiente” combina uma “versão” com uma “configuração” e as implementa. Os próprios executáveis são carregados como arquivos do Amazon S3 de antemão e a “versão” é apenas um indicador para isso.

AWS VM Import Export
O VM Import/Export permite que você importe facilmente imagens de máquina virtual de seu ambiente existente para instâncias do Amazon EC2 e as exporte de volta ao sem ambiente local. Esta oferta permite aproveitar os investimentos existentes nas máquinas virtuais que você construiu para atender aos seus requisitos de segurança de TI, de gerenciamento de configurações e de conformidade trazendo essas máquinas virtuais para o Amazon EC2 como instâncias prontas para usar. Também é possível exportar instâncias importadas de volta para sua infraestrutura de virtualização local, o que permite implementar cargas de trabalho por toda sua infraestrutura de TI.
O VM Import/Export está disponível sem nenhuma taxa adicional além das taxas padrão de uso para o Amazon EC2 e o Amazon S3.
Para importar imagens, use a ILC da AWS ou outras ferramentas de desenvolvedor para importar uma imagem de máquina virtual (VM) do seu ambiente VMware. Se você usa a plataforma de virtualização do VMware vSphere, também pode usar o AWS Management Portal para vCenter para importar a VM. Como parte do processo de importação, o VM Import converte a VM em uma AMI do Amazon EC2, que pode ser usada para executar instâncias do Amazon EC2. Após importar suas VMs, você poderá aproveitar a flexibilidade, a escalabilidade e o monitoramento da Amazon por meio de produtos como Auto Scaling, Elastic Load Balancing e CloudWatch para oferecer suporte às imagens importadas.
Você pode exportar instâncias EC2 importadas anteriormente utilizando as ferramentas de API do Amazon EC2. Basta especificar a instância alvo, o formato do arquivo da máquina virtual e um bucket do S3 de destino e o VM Import/Export exportará automaticamente a instância para o bucket S3. Em seguida, você pode fazer o download e executar a VM exportada em sua infraestrutura de virtualização local.
Você pode importar VMs do Windows e do Linux que usam os formatos de virtualização do VMware ESX ou Workstation, do Microsoft Hyper-V e do Citrix Xen. E você pode exportar instâncias EC2 importadas anteriormente para os formatos VMware ESX, Microsoft Hyper-V ou Citrix Xen. Para obter uma lista completa dos sistemas operacionais, versões e formatos compatíveis, consulte a seção VM Import do Amazon EC2 User Guide. Planejamos adicionar suporte a mais sistemas operacionais, versões e formatos no futuro.

Networking
Amazon ELB
O Amazon Elastic Load Balancer é o serviço AWS responsável por proporcionar o equilíbrio das cargas de trabalho, requisições e acessos aos sistemas e aplicações.
Ele realiza todo o trabalho de distribuir o tráfego que entra através dos aplicativos, ou ainda da rede, e envia para outros destinos, como Amazon EC2, endereços IP ou containers, que podem estar em diferentes zonas de disponibilidade, transformando a performance de tecnologia das empresas em High Performance Computing (HPC).
O Amazon Elastic Load Balancer consegue dimensionar a sua distribuição à medida que o tráfego aumenta ou muda com o passar dos dias.
Inclusive, ele também consegue dimensionar de forma automática para a grande maioria de cargas de trabalho.

Amazon Route 53
Além de oferecer diversos outros serviços, a AWS também possui o Amazon Route 53 que, na prática, é um web service baseado em DNS (Domain Name System) totalmente na nuvem e muito escalável e disponível.
Ele foi criado para proporcionar aos desenvolvedores e também empresas uma forma muito confiável e também econômica de orientar os usuários que são finais para os aplicativos disponíveis na internet.
Sua principal função é fazer a conversão de nomes como www.exemplo.com para endereços IP como, por exemplo, 192.0.0.2, que são usados por diversos computadores para se comunicarem entre si.
Além disso, o Amazon Route 53 também oferece suporte ao IPv6, que é muito utilizado atualmente por diversas companhias.
O Amazon Route 53 consegue se conectar com muita eficiência e rapidez as solicitações que são feitas pelos usuários e executa elas utilizando uma infraestrutura na AWS, como, por exemplo, as instâncias EC2, Elastic Load Balance, load balancers os buckets do Amazon S3.
Com o Amazon Route 53 você também será capaz de criar configurações que conseguem rotear os usuários finais para infraestruturas que estão fora do ambiente AWS.

Amazon VPC
A Amazon Virtual Private Cloud (Amazon VPC) permite iniciar recursos da AWS em uma rede virtual definida por você. Essa rede virtual se assemelha a uma rede tradicional que você operaria no seu datacenter, com os benefícios de usar a infraestrutura dimensionável da AWS.

AWS Direct Connect
O serviço de nuvem AWS Direct Connect é o caminho mais curto para seus recursos na AWS. Seu tráfego de rede permanece todo o tempo na rede global da AWS e nunca entra na Internet pública. Isso reduz as probabilidades de gargalos ou aumentos inesperados de latência. Ao criar uma nova conexão, você pode escolher uma conexão hospedada fornecida por um parceiro de entrega do AWS Direct Connect ou uma conexão dedicada da AWS e implantá-la em mais de 100 locais do AWS Direct Connect ao redor do mundo. Com o AWS Direct Connect SiteLink, você pode enviar dados entre locais do AWS Direct Connect para criar conexões privadas de rede entre os escritórios e datacenters na sua rede global.

Storage
Amazon Elastic Block Store (Amazon EBS)
O Amazon Elastic Block Store (Amazon EBS) oferece volumes de armazenamento em bloco para usar com instâncias do EC2. Os volumes do EBS se comportam como dispositivos de bloco brutos e não formatados. Você pode montar esses volumes como dispositivos em suas instâncias. Os volumes EBS que estão anexados a uma instância são expostos como volumes de armazenamento que persistem independentemente da vida útil da instância. Você pode criar um sistema de arquivos sobre esses volumes ou utilizá-los da maneira que utilizaria um dispositivo de bloco (como um disco rígido). Você pode alterar dinamicamente a configuração de um volume anexado a uma instância.
O Amazon EBS é recomendado para dados que devem ser rapidamente acessíveis e requerem persistência no longo prazo. Os volumes do EBS são especialmente adequados ao uso como armazenamento principal para sistemas de arquivos, bancos de dados ou para todas as aplicações que necessitem de atualizações granulares finas e acesso ao armazenamento em nível de bloco bruto e não formatado. O Amazon EBS é ideal para aplicações no estilo de banco de dados que utilizam leituras e gravações aleatórias, bem como para aplicações com alta taxa de transferência que executam leituras e gravações longas e contínuas.
Amazon Glacier
O Amazon S3 Glacier é uma classe de armazenamento do Amazon S3 segura, durável e de custo extremamente baixo para arquivamento de dados e backup de longo prazo.
Com o S3 Glacier, os clientes podem armazenar seus dados de maneira econômica por meses, anos ou até décadas. O S3 Glacier permite que os clientes descarregem os encargos administrativos de operação e dimensionamento do armazenamento para AWS para que não precisem se preocupar com planejamento de capacidade, provisionamento de hardware, replicação de dados, detecção e recuperação de falhas de hardware ou migrações de hardware demoradas.

AWS Import/Export
O VM Import/Export permite que você importe facilmente imagens de máquina virtual de seu ambiente existente para instâncias do Amazon EC2 e as exporte de volta ao sem ambiente local. Esta oferta permite aproveitar os investimentos existentes nas máquinas virtuais que você construiu para atender aos seus requisitos de segurança de TI, de gerenciamento de configurações e de conformidade trazendo essas máquinas virtuais para o Amazon EC2 como instâncias prontas para usar. Também é possível exportar instâncias importadas de volta para sua infraestrutura de virtualização local, o que permite implementar cargas de trabalho por toda sua infraestrutura de TI.
O VM Import/Export está disponível sem nenhuma taxa adicional além das taxas padrão de uso para o Amazon EC2 e o Amazon S3.
Para importar imagens, use a ILC da AWS ou outras ferramentas de desenvolvedor para importar uma imagem de máquina virtual (VM) do seu ambiente VMware. Se você usa a plataforma de virtualização do VMware vSphere, também pode usar o AWS Management Portal para vCenter para importar a VM. Como parte do processo de importação, o VM Import converte a VM em uma AMI do Amazon EC2, que pode ser usada para executar instâncias do Amazon EC2. Após importar suas VMs, você poderá aproveitar a flexibilidade, a escalabilidade e o monitoramento da Amazon por meio de produtos como Auto Scaling, Elastic Load Balancing e CloudWatch para oferecer suporte às imagens importadas.
Você pode exportar instâncias EC2 importadas anteriormente utilizando as ferramentas de API do Amazon EC2. Basta especificar a instância alvo, o formato do arquivo da máquina virtual e um bucket do S3 de destino e o VM Import/Export exportará automaticamente a instância para o bucket S3. Em seguida, você pode fazer o download e executar a VM exportada em sua infraestrutura de virtualização local.

AWS Storage Gateway
Essa ferramenta fenomenal foi projetada para conectar o armazenamento na nuvem pública da AWS aos seus aplicativos locais. O storage gateway da AWS também ajuda a economizar custos devido à transferência segura e rápida entre o software local e o armazenamento baseado em nuvem.
Você pode fazer backup de pontos de recuperação de seus sistemas no local. No entanto, isso não é tudo. O AWS Storage Gateway também pode espelhar dados locais. A Amazon projetou o storage gateway para ser usado como armazenamento extra diretamente com a AWS.

Backup e restore
O intuito dessa estratégia é realizar o armazenamento dos backups remotamente, para que, no caso de algum incidente, esses dados estejam salvaguardados e possam ser restaurados. Caso não possua nenhum tipo de estratégia de DR, pode ser um bom início. Essa estratégia possui uma adesão rápida e fácil, além de bastante econômica, pois somente incorrerá custos de armazenamento.
Apesar do custo reduzido, possuem RT e RP elevados, devido a periodicidade do processo de backup e ao tempo de transferência de entrada e saída de dados realizados.
Normalmente os serviços utilizados nessa estratégia são: Amazon S3 e Amazon Glacier para armazenamento, AWS Storage Gateway, como appliance de armazenamento. Para conectividade entre os sites, Direct Connect ou VPC/VPN.
Existem serviços que acelerarão o envio de dados, ideal para fazer as cargas iniciais, que são AWS Import/Export/Snowball.
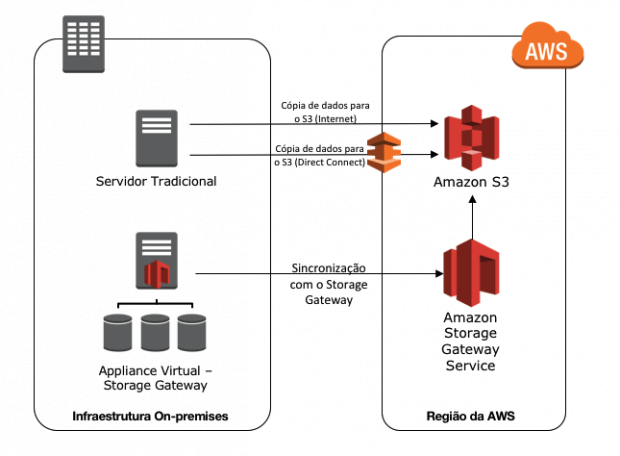
Pilot Light
Nessa estratégia teremos parte do workload, normalmente uma replicação de dados, no ambiente de DR.
Em linhas gerais, consiste no sincronismo dos principais dados do workload e os outros componentes da arquitetura (servidores, balanceadores de carga, dentre outros) são também disponibilizados, porém não estão operacionais, aguardando algum incidente para a sua devida ativação.
O custo dessa arquitetura é um pouco mais elevado, quando se compara com a estratégia anterior. No entanto, haverá redução de RT e RP, pois os principais dados já estão replicados no ambiente de DR.
Os principais serviços utilizados nessa estratégia são: EC2 para computação, EBS para armazenamento de blocos ligados nas EC2, para questões de rede VPC, RDS, que atuará como Banco de Dados relacional como serviço, o balanceador de carga ELB, serviço de DNS Route 53 e Elastic Beanstalk.
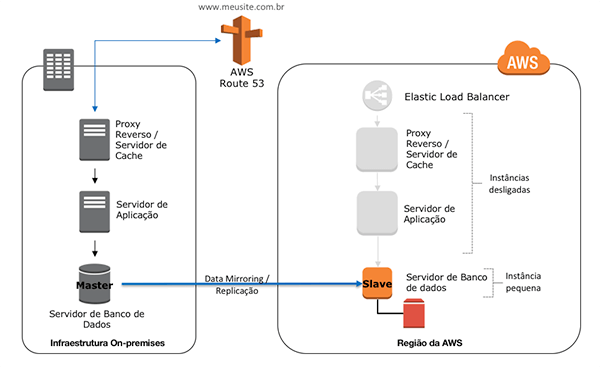
Warm Standby
Com o uso dessa estratégia, teremos o ambiente de DR operacional, no entanto, com poder computacional reduzido. Em caso de incidente, basta ajustar as capacidades necessárias e realizar os devidos apontamentos para o ambiente de DR.
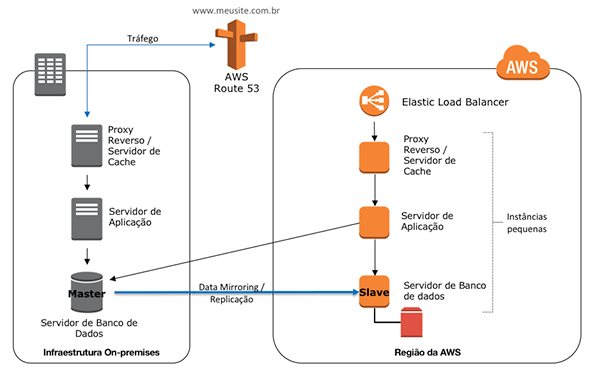
O RT e RP nessa estratégia serão ainda menores, comparando com a pilot-light, visto que existirá dois ambientes operacionais, mas o custo também, necessariamente, será maior, visto que teremos mais componentes ativos.
Os serviços utilizados nessa estratégia são semelhantes aos da estratégia de Pilot Light: EC2 para computação, EBS para armazenamento de blocos ligados nas EC2, para questões de rede VPC, RDS, que atuará como Banco de Dados relacional como serviço, o balanceador de carga ELB, serviço de DNS Route 53 e Elastic Beanstalk.
Multi-site
Consiste em ter dois ambientes completamente operacionais, que são usados de forma ativa. No caso de algum incidente, basta não mais enviar requisição para o ambiente afetado; dessa forma, a sua interrupção poderá ser imperceptível, pois as requisições começarão a ser enviadas para o ambiente em DR, pois, teremos dois ambientes em pleno funcionamento. Dependendo da carga existente, o ambiente de recovery sofrerá ajustes necessários de escalação para suportar a carga existente.
Nessa estratégia o RT e RP são mínimos, pois os dois ambiente estarão em plena atividade. O custo dentre todas as estratégias tende a ser o maior, visto que todos os componentes da arquitetura estarão ligados.
Vale salientar, devido a complexidade da implementação desse tipo de estratégia, em alguns momentos, não será possível a utilização em determinados workloads.
Os serviços utilizados nessa estratégia são semelhantes aos da estratégia Warm Standby: EC2 para computação, EBS para armazenamento de blocos ligados nas EC2, para questões de rede VPC, RDS o qual atuará como Banco de Dados relacional como serviço, o balanceador de cargas ELB, serviço de DNS Route 53 e Elastic Beanstalk.
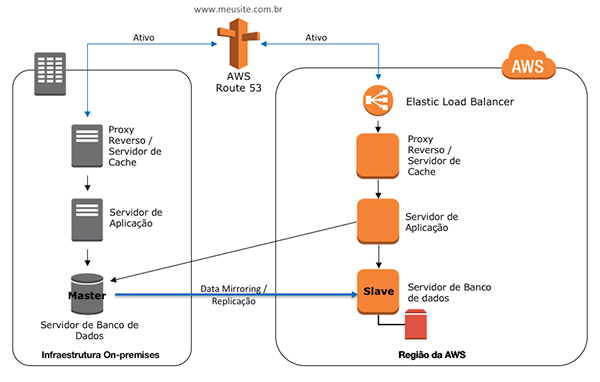
Casos de uso de DR
Neste tópico, abordaremos alguns casos de DR e suas arquiteturas. Cada caso será analisado em função das camadas que compõe a sua arquitetura e, para cada uma, serão detalhados os mecanismos de preparação e recuperação, de modo a satisfazer o RPO e RTO da organização.
Perceba que nem sempre será possível criar um ambiente de DR na AWS que seja idêntico ao ambiente on-premises. Assim, adequações devem ser feitas de modo a aproveitar as funcionalidades dos serviços da AWS.
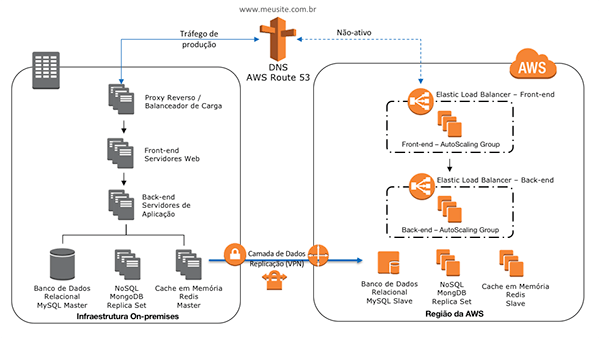
Arquitetura Web – Warm Standby
Este cenário refere-se a uma arquitetura de um sistema Web rodando em uma estrutura on-premises, com estratégia de DR Warm Standby.
A arquitetura está dividida nos seguintes componentes: DNS, camada de computação com balanceadores de carga, servidores web de front-end, servidores de aplicação de back-end, camada de persistência com banco de dados relacional MySQL, NoSQL e MongoDB e cache em memória Redis.
Será utilizada a estratégia de Warm Standby, onde o ambiente de recovery é mínimo, mas perfeitamente funcional. Em caso de desastre, o ambiente será escalado para suportar a carga de produção.
Camada de redes e comunicação
A camada de redes e comunicação define como os sistemas e recursos serão disponibilizados e acessados de maneira segura pelos usuários. Em caso de desastre, é desejável que a experiência de como os usuários acessam um serviço não sofra grandes impactos, sendo os acessos redirecionados para o ambiente de recovery.
É possível implementar um mecanismo de comunicação segura através de uma VPN entre o ambiente on-premises e a AWS.
DNS
Para redirecionar os acessos para o ambiente de recovery, deve-se realizar o failover de DNS.
Com o AWS Route 53 é possível realizar o failover de DNS de maneira manual ou de maneira automática através de health checks , que redireciona o tráfego em função da disponibilidade dos ambientes. Você também pode utilizar seu serviço de DNS on-premises para realizar o failover.
Camada de computação
O grande desafio da camada de servidores está em manter o ambiente de recovery atualizado em relação ao ambiente de origem. Atividades como aplicações de patch, atualizações de software e arquivos de configurações, devem ser refletidas de modo a garantir a perfeita operacionalização do ambiente de recovery.
Balanceador de carga
Para realizar o balanceamento de cargas de suas aplicações no ambiente de recovery é possível criar uma solução com a implantação de proxys em instâncias EC2.
O Amazon Elastic Load Balancing é outra opção para o balanceamento de cargas. Junto com o Auto Scaling , é possível montar uma estrutura capaz de escalar o ambiente mínimo de recovery, adicionando novas instâncias EC2 de forma automática.
Desta maneira, em um cenário de desastre, ELBs e Auto Scalings já estarão devidamente configurados e as aplicações estarão preparadas para suportar a carga do ambiente de origem.
Servidores de front-end e back-end
De modo a satisfazer RPO e RTO da arquitetura Warm Standby, suas aplicações no ambiente de recovery devem ser perfeitamente funcionais, sendo uma versão mínima da infraestrutura do ambiente de origem.
Crie e mantenha imagens atualizadas de seus servidores de modo a lançar seu ambiente de recovery de maneira rápida. As Amazon Machine Images (AMIs) são imagens que provêm as informações necessárias para lançar instâncias EC2 com serviços totalmente funcionais.
Você também pode iniciar instâncias EC2 de uma máquina virtual que você importou de um ambiente virtualizado com Citrix Xen, Microsoft Hyper-V ou VMWare através do AWS VM Import Export.
Realize o escalonamento vertical de maneira manual, iniciando suas aplicações em instâncias EC2 maiores conforme o necessário. O escalonamento vertical implica em downtime, necessário para que as instâncias EC2 sejam paradas e reiniciadas com um tamanho maior, causando impacto no RTO. Para realizar o escalonamento horizontal através de um balanceador de carga, aumente a sua frota de instâncias EC2 de maneira manual ou deixe o Auto Scaling adicionar novas instâncias de maneira automática.
Utilize o Amazon CloudWatch para realizar o monitoramento de seu ambiente. Você pode utilizá-lo para colher métricas, obter visibilidade da utilização de seus recursos e reagir de modo a manter suas aplicações funcionando.
Camada de dados
A camada de dados é a mais sensível em um projeto de Disaster Recovery. RPO e RTO são influenciados diretamente pelo mecanismo utilizado na replicação desta camada para o ambiente de recovery. Em linhas gerais, quanto mais sofisticado for o mecanismo, menores serão os RPO e RTO alcançados. Em um extremo estão as estratégias de backup e recuperação dos dados e em outro estão os mecanismos para montagem de clusters de base de dados com múltiplos nós mestre ativos.
Banco de dados relacional – MySQL
O objetivo é replicar e manter sincronizado o estado do banco de dados relacional MySQL para o ambiente derecovery. O MySQL permite implementar diversos métodos de replicação com diferentes tipos de sincronização.
O DR Warm Standby pode ser implementado através de uma arquitetura master/slave, com o nó master rodando e replicando dados do ambiente on-premises para o nó slave em uma instância EC2 na AWS. Também é possível utilizar o Amazon RDS para MySQL como o nó slave dessa replicação .
Quando o desastre ocorrer, é necessário escalar o ambiente mínimo de recovery para suportar a transferência de carga. Para tal, redimensione a instância EC2 utilizada como nó slave (implica em downtime do banco de dados).
O nó slave deve ser promovido para tornar-se o novo master. Uma maneira de manter as aplicações informadas sobre a localização do nó master de maneira transparente é ter uma entrada de DNS dinâmico.
Banco de dados NoSQL – MongoDB
Em geral, bancos de dados NoSQL possuem mecanismos de replicação de dados, com o objetivo de prover alta disponibilidade do serviço.
Com o MongoDB é possível montar diferentes arquiteturas de replicação de dados. A principal estrutura da replicação é o MongoDB Replica Set , que mantém o mesmo conjunto de dados e provêm redundância e alta disponibilidade ao ambiente. Para maiores detalhes, verifique a documentação oficial do MongoDBm.
Cache em memória – Redis
Para manter sincronizado o estado do cache em memória, será feita replicação em uma arquiteturamaster/slave do Redis. Em caso de desastre será necessário forçar manualmente para que o nó slave do cluster torne-se o novo master, realizando o cluster failover.
Arquitetura Cliente Servidor – Warm Standby
Nesse tópico será discutido DR de aplicação do tipo Cliente Servidor.
Consideramos que esse workload será dividido nas seguintes camadas, DNS, aplicação/acesso dos usuários (Terminal Services), banco de dados e repositório de usuários (LDAP).
Utilizaremos a estratégia de Warm Standby, sendo assim, a ideia é disponibilizar todos os componentes da arquitetura no ambiente de DR, mantendo-os desligados, e replicar a camada de banco de dados entre os dois ambiente.
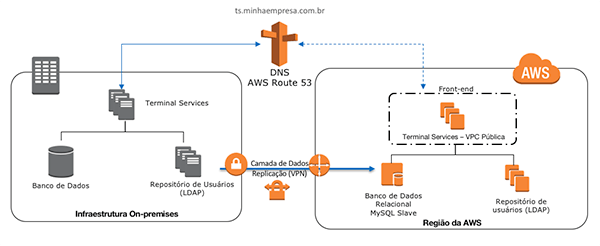
Camada de DNS
No que tange as questões de DNS, com a utilização do Route 53, como já mencionado anteriormente, utilizaremos a funcionalidade de health check.
Para os apontamentos tanto do concentrador de conexões de usuário (Terminal Services), o qual é a porta de entrada dos usuários, assim como para o banco de dados. Dessa forma, ao acontecer o incidente, o acesso será direcionado para o host que estará apto para receber as conexão.
Camada de servidores de autenticação
Para essa camada específica, realizaremos a replicação do repositório de usuário, utilizando servidor de réplica EC2 para que no caso de incidente, teremos sempre pelo menos um disponível, utilizando-se dessa replicação, teremos repositórios com os mesmos usuários.
É necessário realizar os apontamentos na aplicação em questão para os dois repositórios de usuário, pois no caso de incidente, pelo menos um deles estará apto para atender as solicitações.
Camada de Dados
Em se tratando de banco de dados, é necessário realizar replicação dos dados entre os bancos dos ambientes envolvidos.
O intuito desse documento não é entrar profundamente nas estratégias de replicação, deixando a cargo do implementador a escolha da melhor forma de manter os dados sincronizados.
Repositório de arquivos – backup e restore
A AWS fornece diversos serviços os quais ajudarão a atender os requisitos das arquiteturas de backup and restore.
Podemos desde utilizar ferramentas de parceiros/terceiros, até construir as próprias ferramentas para realização de backup.
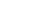
Conforme mencionado anteriormente, o serviço de Storage Gateway facilita a integração entre os ambientes para a realização de backup, dessa forma, podemos persistir dados no S3 e/ou Glacier.
A figura abaixo é um exemplo de um workload, o qual possui uma infraestrutura on-premises e os backups de dados enviados para a infraestrutura em nuvem. Caso aconteça algum desastre, como o backup dos dados, já estão persistidos em nuvem computacional, pode ser inicializado rapidamente a instalação desse ambiente em nuvem e direcionar os usuários para esse novo ambiente operacional.
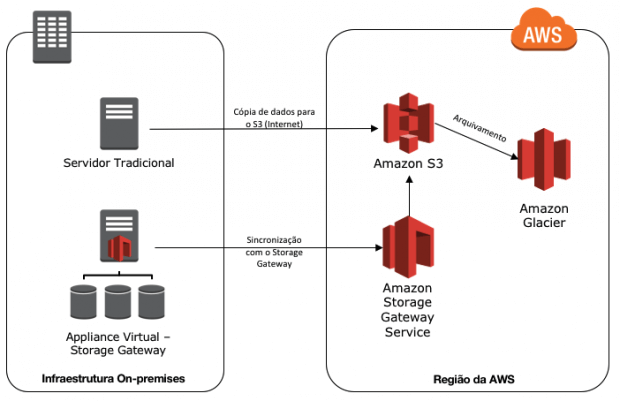
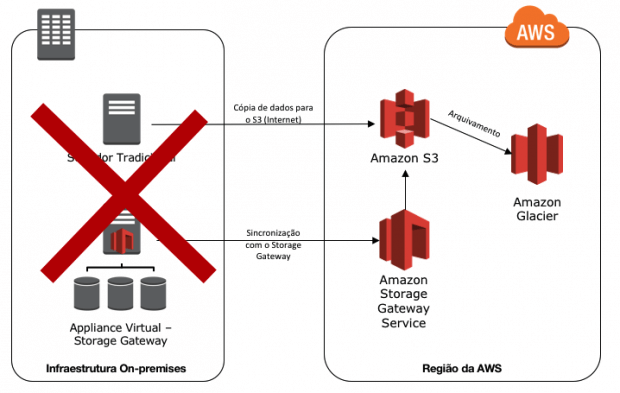
Utilizando Storage Gateway
O serviço de Storage Gateway, facilita a comunicação com a nuvem computacional. Com isso, você consegue escolher entre as três modalidades existente, qual mais se adequa para a sua necessidade. O detalhamento das modalidades será exposto abaixo.
- Gateway-Cached Volumes: Pode armazenar seus dados no Amazon S3 e reter os dados mais acessados em seus discos locais. Nessa modalidade, o tamanho do seu repositório, pode ser maior que o disco físico disponível. É uma excelente opção, caso você queira economizar com armazenamento e deseja ter uma latência menor para os dados mais acessados.
- Gateway-Stored Volumes: Nessa modalidade, caso deseje uma baixa latência à todos os dados armazenados on-premises e de forma assíncrona realizar backups para o Amazon S3.
- Gateway-Virtual Tape Library (VTL): Utilizando dessa modalidade, você possuirá uma biblioteca virtual de fitas, as quais podem ser plugadas em seus softwares de backup. A persistência dos dados será feita em Amazon S3 ou em Glacier.
Utilizando ferramentas de parceiros
Para realizar backup de dados, existem ferramentas de parceiros da AWS , as quais facilitam o sincronismo de dados. Fornecendo diversas funcionalidades, desde de possibilidade de persistência dos dados em S3 e/ou Glacier, assim como a realização de agendamentos de backups ou envio de dados em tempo real.
Dessa forma, você pode realizar schedule do sincronismos de pastas específicas existentes no ambiente de forma simples e rápida. No entanto, com a utilização de ferramentas de parceiros, caso a funcionalidade desejada não esteja disponível, não terá flexibilidade de customizar algo para atender as suas necessidades.
Desenvolvendo suas aplicações/scripts
A AWS possui uma rica API e CLI , sendo assim, você poderá construir suas aplicações e scripts da forma que desejar, atendendo aos requisitos necessários do seu negócio.
O Microsoft Azure é uma solução que promove uma transformação muito positiva no negócio e para adotá-lo com segurança na empresa, é importante contar com o apoio de um parceiro Microsoft.
Isso facilita o processo e ajuda a adequar as configurações de acordo com as necessidades do negócio, movendo seus dados de forma segura e sem perdas.
A GATEWAY IT é uma empresa Microsoft Gold Partner, com grande experiência de mercado e equipe especializada. Estamos prontos para te auxiliar na implantação e adaptação à nuvem do Microsoft Azure.
